Java 连接 kafka
说明
1.本文以网易云 kafka 1.1.0 版本进行讲解,关于产品简介以及如何创建 kafka,请参考官网文档
2.本文bootstrap.servers
地址为 c-m1dvx2wwog.kafka.cn-east-1.internal:9092
3.由于 kafka 只能在可用区 B 创建,如果需要在本地调试,需要先在可用区 B 搭建 VPN 连接。OpenVPN 搭建,参考文档
如无法连接,请检查安全组和系统防火墙,请在对应的 VPC 安全组中放行内网访问 9092端口以及允许外网访问 OpenVPN 端口
关于外网连接 openvpn 无法 解析 kafka 域名的问题
我们连接 openvpn 后 ping c-m1dvx2wwog.kafka.cn-east-1.internal 是不行的,需要先在内网的机器上 ping 这个地址拿到 IP 后
[root@vpn ~]# ping c-m1dvx2wwog.kafka.cn-east-1.internal
PING c-m1dvx2wwog.kafka.cn-east-1.internal (192.168.10.154) 56(84) bytes of data.
64 bytes from 192.168.10.154 (192.168.10.154): icmp_seq=1 ttl=64 time=1.33 ms
64 bytes from 192.168.10.154 (192.168.10.154): icmp_seq=2 ttl=64 time=0.740 ms
64 bytes from 192.168.10.154 (192.168.10.154): icmp_seq=3 ttl=64 time=0.502 ms
^C
--- c-m1dvx2wwog.kafka.cn-east-1.internal ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.502/0.859/1.337/0.352 ms用这个 IP 去连接 kafka
创建一个 maven 工程
1.创建一个 maven 工程,在pom.xml 中加入
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>需要注意:kafka-clients的版本必须和kafka安装的版本一致
Producer demo
package KafkaService;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaProducerService {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.10.154:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = null;
try {
producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
String msg = "Message " + i;
producer.send(new ProducerRecord<String, String>("test", msg));
System.out.println("Sent:" + msg);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}}
可以使用KafkaProducer类的实例来创建一个Producer,KafkaProducer类的参数是一系列属性值,下面分析一下所使用到的重要的属性:
bootstrap.servers
properties.put("bootstrap.servers", "192.168.1.110:9092");bootstrap.servers
它是Kafka集群的IP地址,如果Broker数量超过1个,则使用逗号分隔,如”192.168.10.110:9092,192.168.10.110:9092”。
key.serializer&value.serializer
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");序列化类型。 Kafka消息是以键值对的形式发送到Kafka集群的,其中Key是可选的,Value可以是任意类型。但是在Message被发送到Kafka集群之前,Producer需要把不同类型的消
息序列化为二进制类型。本例是发送文本消息到Kafka集群,所以使用的是StringSerializer。
发送Message到Kafka集群
for (int i = 0; i < 100; i++) {
String msg = "Message " + i;
producer.send(new ProducerRecord<String, String>("test", msg));
System.out.println("Sent:" + msg);
}上述代码会发送100个消息到test这个Topic
Topic 要在控制台创建
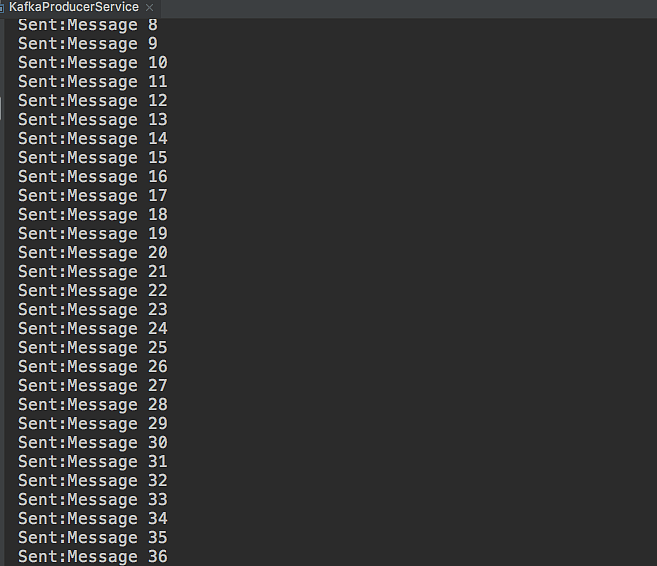
执行上述程序运行结果如下:
Consumer Demo
package KafkaService;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class ConsumerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.10.154:9092");
properties.put("group.id", "group-1");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("test"));
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
}
}可以使用KafkaConsumer类的实例来创建一个Consumer,KafkaConsumer类的参数是一系列属性值,下面分析一下所使用到的重要的属性:
bootstrap.servers:和Producer一样,是指向Kafka集群的IP地址,以逗号分隔。
group.id:Consumer分组ID
key.deserializer and value.deserializer
发序列化。Consumer把来自Kafka集群的二进制消息反序列化为指定的类型。因本例中的Producer使用的是String类型,所以调用StringDeserializer来反序列化
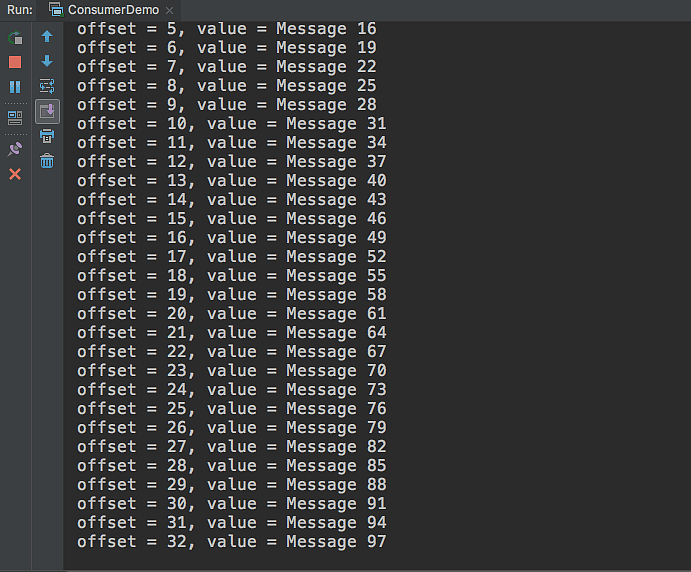
Consumer订阅了Topic为HelloWorld的消息,Consumer调用poll方法来轮循Kafka集群的消息,其中的参数100是超时时间(Consumer等待直到Kafka集群中没有消息为止):
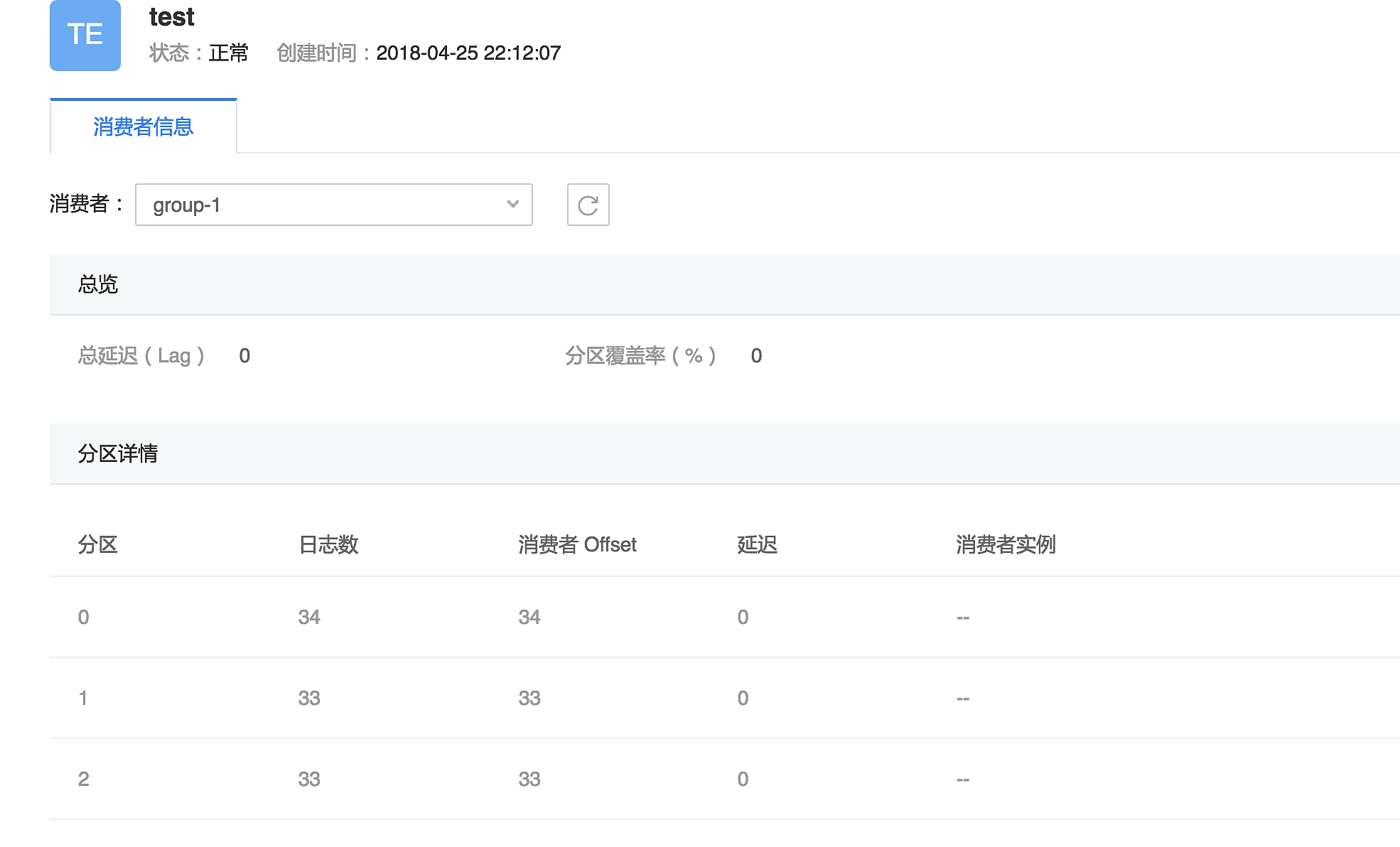
在控制台找到对应的 Topic 可以看到消费者信息